
In today’s world of distributed systems and real-time analytics, keeping data in sync across databases is critical. This blog post walks you through a practical demo of implementing Change Data Capture (CDC) to replicate data from SQL Server to PostgreSQL, using Debezium, Apache Kafka, and Kafka Connect.
We’ll set up a fully functional pipeline that captures changes in SQL Server and streams them to a PostgreSQL sink — all within Docker containers.
📌 What is Change Data Capture (CDC)?
Change Data Capture (CDC) is a technique for identifying and capturing changes made to data in a database. Instead of periodically polling for changes, CDC enables near real-time change propagation by reading the database’s transaction log.
- Real-time data sync between systems
- Reduced overhead compared to full data refreshes
- Event-driven architectures support
- Seamless integration with analytics and microservices platforms
🏗️ System Architecture
Here’s the overall architecture of our CDC pipeline:
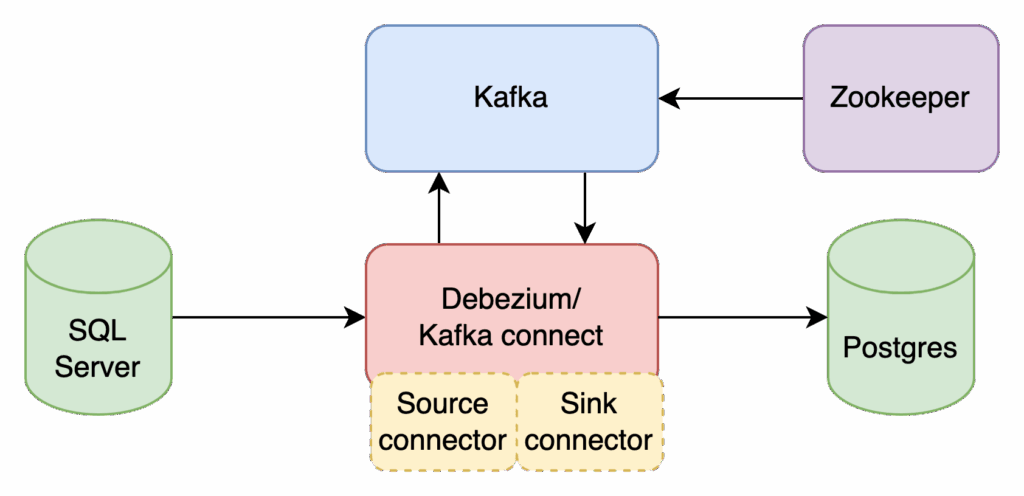
- SQL Server with CDC enabled: Source system where changes originate.
- Debezium/Kafka connect: Handles integration with source and sink systems.
- Kafka: Acts as the streaming backbone.
- PostgreSQL: The destination system (sink).
🧰 Prerequisites
- Docker & Docker Compose
- curl (for interacting with Kafka Connect)
- Basic knowledge of SQL and Docker
🚀 Step-by-Step Setup
📂 Project Files
All configuration files are available in the kamranzafar/cdc-demo GitHub repository. Clone this repository on your local machine. This repository contains the following source files, which are required by this setup.
- Docker Compose: docker-compose.yml
- SQL Server Setup: setup_sqlserver_source.sql
- PostgreSQL Setup: setup_postgres_sink.sql
- Connectors:
1️⃣ Start the Environment
Using command line, run the following command to start the services:
docker-compose -f docker/docker-compose.yml up2️⃣ Configure SQL Server
✅ Enable SQL Server Agent
Log inside the SQL Server docker container and run the following command.
/opt/mssql/bin/mssql-conf set sqlagent.enabled trueRestart the container after enabling the agent.
🧱 Create and Enable CDC on Source Table
CREATE DATABASE TESTDB;
USE TESTDB;
CREATE TABLE messages (
id INT,
msg VARCHAR(255)
);
EXEC sys.sp_cdc_enable_db;
EXEC sys.sp_cdc_enable_table
@source_schema = N'dbo',
@source_name = N'messages',
@role_name = NULL;
3️⃣ Setup PostgreSQL Sink Table
CREATE TABLE messages (
"id" INT8 NOT NULL,
"msg" VARCHAR(255),
PRIMARY KEY ("id")
);
4️⃣ Configure Kafka Connect Connectors
Run the following to deploy the source and sink connectors:
curl -i -X POST -H "Accept:application/json" \
-H "Content-Type:application/json" \
localhost:8083/connectors -d @source-connector.json
curl -i -X POST -H "Accept:application/json" \
-H "Content-Type:application/json" \
localhost:8083/connectors -d @sink-connector.json
🧪 Testing the Pipeline
➕ Insert Data into SQL Server
INSERT INTO dbo.messages VALUES (1, 'message 1');
INSERT INTO dbo.messages VALUES (2, 'hello world');
🔍 Query Data in PostgreSQL
SELECT * FROM messages;You should see the replicated rows appear!
🧩 Summary
In this demo we set up a real-time CDC pipeline using:
- SQL Server with CDC enabled
- Debezium connector
- Apache Kafka
- Kafka Connect
- PostgreSQL sink
This architecture is ideal for syncing data between systems, powering real-time dashboards, or feeding data lakes.
📎 Next Steps
- Support updates and deletes
- Handle schema evolution
- Secure your connectors and broker
- Monitor pipeline health with tools like Kafka UI or Prometheus



